TH-PAD: Talking Head Generation with Probabilistic Audio-to-Visual Diffusion Priors



Given only an audio source and an arbitrary identity image, our system can generate a video with natural-looking and diverse facial motions (pose, expression, blink & gaze), while maintaining accurate audio-lip synchronization. Here we show randomly sampled sequences from our diffusion prior for two identities, note that the lip-irrelevant facial motion varies but the lip is still in-sync.
Abstract
We introduce a novel framework for one-shot audio-driven talking head generation. Unlike prior works that require additional driving sources for controlled synthesis in a deterministic manner, we instead sample all holistic lip-irrelevant facial motions (i.e. pose, expression, blink, gaze, etc.) to semantically match the input audio while still maintaining both the photo-realism of audio-lip synchronization and overall naturalness. This is achieved by our newly proposed audio-to-visual diffusion prior trained on top of the mapping between audio and non-lip representations. Thanks to the probabilistic nature of the diffusion prior, one big advantage of our framework is it can synthe-size diverse facial motion sequences given the same audio clip, which is quite user-friendly for many real applications. Through comprehensive evaluations of public benchmarks, we conclude that (1) our diffusion prior outperforms auto-regressive prior significantly on all the concerned metrics; (2) our overall system is competitive with prior works in terms of audio-lip synchronization but can effectively sample rich and natural-looking lip-irrelevant facial motions while still semantically harmonized with the audio input.
Video
Overview
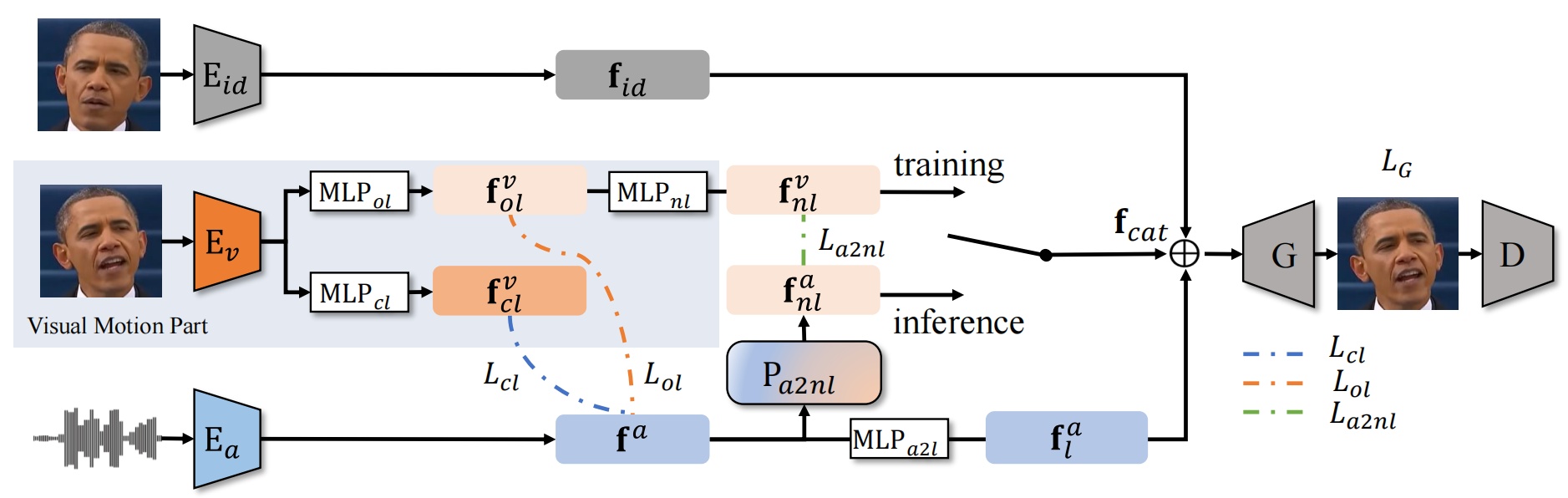
The overall pipeline of our proposed framework. The dotted lines represent the loss functions that are used only in training, i.e., L_{cl}, L_{ol} and L_{a2nl}. L_{G} is the training loss for visual non-lip space. Note that there is a switch in the figure, which means the different forward processes in training and inference: in training, the concatenated feature f_{cat} = cat(f_{id}, f_{nl}^{v}, f_{l}^a); at inference stage, f_{cat} = cat(f_{id}, f_{nl}^a, f_{l}^a). Thus, the visual motion part is not needed anymore at the inference stage.
Generation Results
TH-PAD is able to produce audio-drivin talking head videos for different identities. Unlike most other methods that require additional driving signals for non-lip motions, it can sample reasonable signals from the audio source.
TH-PAD can also generate with audio sources in different languages.
Compared with other methods, TH-PAD is able to generate richer facial motions with more accurate lip motion. Moreover, it can bring about different results for the same audio source.
Ablation Study
Without velocity loss L_{vel}, the prediction becomes unstable. While training without the editing mechanism, we applied editing only during sampling as in MDM, and observed that it jitters between adjacent frames.
Citation
@inproceedings{yu2023thpad,
title={Talking Head Generation with Probabilistic Audio-to-Visual Diffusion Priors},
author={Zhentao Yu, Zixin Yin, Deyu Zhou, Duomin Wang, Finn Wong and Baoyuan Wang},
booktitle={ International Conference on Computer Vision (ICCV)},
year={2023}
}