|
Email: zixin.yin[at]connect.ust.hk Google Scholar Github I am currently a PhD student at The Hong Kong University of Science and Technology, under the supervision of Prof. Lionel Ni (president of HKUST-gz) and Prof. Harry Shum (former executive vice president of Microsoft), since 2021. From April 2023 to April 2025, I served as the co-founder of Morph Studio. Prior to that, I worked closely with Baoyuan Wang and Duomin Wang as a research intern at Xiaobing.ai starting in 2022. My research interests include image and video generation, visual editing, and talking head synthesis. From August 2019 to May 2021, I worked with Prof. Carlo H. Séquin at UC Berkeley on the graphics and CAD project JIPCAD. I received my B.S. from the Department of Computer Science and Technology (Honors Science Program) and completed the Honors Youth Program (少年班) at Xi'an Jiaotong University in 2021. |

|
|
|

|
Zixin Yin, Ling-Hao Chen, Lionel M. Ni, Xili Dai ACM SIGGRAPH Conference and Exhibition on Computer Graphics and Interactive Techniques in Asia, ACM SIGGRAPH Asia 2025, Oral Presentation [PDF] [Project] [Code] ConsistEdit is a training-free attention control method for MM-DiT that enables precise, structure-aware image and video editing. It supports multi-round edits with strong consistency and achieves state-of-the-art performance without manual design or test-time tuning. |
|
|
Ling-Hao Chen, Yuhong Zhang, Zixin Yin, Zhiyang Dou, Xin Chen, Jingbo Wang, Taku Komura, Lei Zhang, ACM SIGGRAPH Conference and Exhibition on Computer Graphics and Interactive Techniques in Asia, ACM SIGGRAPH Asia 2025, Oral Presentation [PDF] [Project] [Code] [Demo Video] This work addresses animation retargeting across characters with differing skeletal topologies. Motion2Motion is a novel, training-free framework that requires only a few target motions and sparse bone correspondences. It overcomes topological inconsistencies without large datasets. Extensive evaluations show strong performance in both similar and cross-species settings, with practical applications in user-facing tools. Code and data will be released. |

|
Zixin Yin, Xili Dai, Ling-Hao Chen, Deyu Zhou, Jianan Wang, Duomin Wang, Gang Yu, Lionel M. Ni, Lei Zhang, Heung-Yeung Shum arXiv, 2508.09131, [PDF] [Project] [Code(coming soon)] We introduce ColorCtrl, a training-free method for text-guided color editing in images and videos. It enables precise, word-level control of color attributes while preserving geometry and material consistency. Experiments on SD3, FLUX.1-dev, and CogVideoX show that ColorCtrl outperforms existing training-free and commercial models, including GPT-4o and FLUX.1 Kontext Max, and generalizes well to instruction-based editing frameworks. |

|
Zixin Yin, Xili Dai, Duomin Wang, Xianfang Zeng, Lionel M. Ni, Gang Yu, Heung-Yeung Shum arXiv, 2509.12203, [PDF] [Project] [Code(coming soon)] LazyDrag, a drag-based image editing method for Multi-Modal Diffusion Transformers, eliminates implicit point matching, enabling precise geometric control and text guidance without test-time optimization. |
|
|
Duomin Wang, Wei Zuo, Aojie Li, Ling-Hao Chen, Xinyao Liao, Deyu Zhou, Zixin Yin, Xili Dai, Daxin Jiang, Gang Yu arXiv, 2509.06155, [PDF] [Project] [Code] [Model weights] [Verse-Bench] We introduce UniVerse-1, a unified, Veo-3-like model capable of simultaneously generating coordinated audio and video. To enhance training efficiency, we bypass training from scratch and instead employ a stitching of expertise technique. |
|
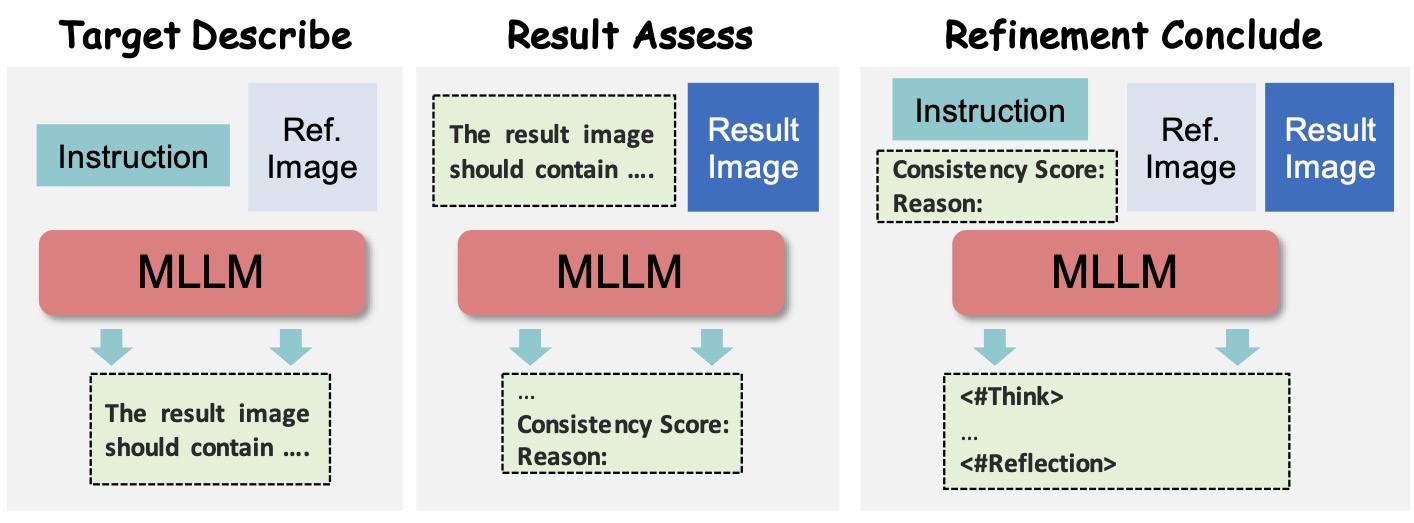
Step1X-Image Team arXiv, 2511.22625, [PDF] [Code] We show that unlocking MLLM reasoning via a thinking–editing–reflection loop significantly improves image editing accuracy by enhancing instruction understanding and automatic error correction, achieving consistent gains over state-of-the-art diffusion-based editors such as Step1X-Edit and Qwen-Image-Edit. |
|
|
Youliang Zhang, Zhaoyang Li, Duomin Wang, Jiahe Zhang, Deyu Zhou, Zixin Yin, Xili Dai, Gang Yu, Xiu Li arXiv, 2507.09862, [PDF] [Project] [Code] [Dataset] We introduce SpeakerVid-5M, the first large-scale dataset designed specifically for the audio-visual dyadic interactive virtual human task. |
|
|
Zhentao Yu*, Zixin Yin*, Deyu Zhou*, Duomin Wang, Finn Wong, Baoyuan Wang 2023 IEEE International Conference on Computer Vision, ICCV 2023, [PDF] [Project] [BibTeX] We introduce a simple and novel framework for one-shot audio-driven talking head generation. Unlike prior works that require additional driving sources for controlled synthesis in a deterministic manner, we instead probabilistically sample all the holistic lip-irrelevant facial motions (i.e. pose, expression, blink, gaze, etc.) to semantically match the input audio while still maintaining both the photo-realism of audio-lip synchronization and the overall naturalness. |
|
|
Duomin Wang, Yu Deng, Zixin Yin, Heung-Yeung Shum, Baoyuan Wang 2023 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2023, [PDF] [Project] [Code] [BibTeX] We present a novel one-shot talking head synthesis method that achieves disentangled and fine-grained control over lip motion, eye gaze&blink, head pose, and emotional expression. We represent different motions via disentangled latent representations and leverage an image generator to synthesize talking heads from them. |
| (* means equal contribution) | |
|
The website template was adapted from Duomin Wang. |